Technical Experiment · December 2025
Intent-Aware Routing for Compound AI: Experimenting with NVIDIA NIM Orchestrator-8B
The future of AI isn’t one giant model doing everything—it’s multiple specialized models working together. But how do you route requests to the right model? I experimented with NVIDIA’s Orchestrator-8B to test intent-aware routing in compound AI systems.
The Age of Compound AI Systems
Here’s what Berkeley AI researchers discovered: state-of-the-art AI results are increasingly obtained by compound systems with multiple components, not just monolithic models.
What’s a compound AI system? According to Berkeley AI Research, it’s a system that tackles AI tasks using multiple interacting components—multiple calls to models, retrievers, databases, and external tools working together.
This isn’t theoretical. Research from Databricks found that:
- 60% of LLM applications use some form of retrieval-augmented generation (RAG)
- 30% use multi-step chains with multiple model calls and tools
Think about Google’s AlphaCode 2—it doesn’t just use one model to generate code. It uses LLMs to generate up to 1 million possible solutions for a programming task, then uses other models to filter and rank them down to the best answer. That’s a compound AI system.
The Routing Problem Nobody Talks About
Once you accept that production AI needs multiple models, you hit a new problem: which model handles which request?
You need different models for different reasons—what I call “horses for courses”:
🎯 Quality
Complex legal reasoning? Claude Opus. Simple email classification? Gemini Flash works fine.
⚡ Performance
Real-time chatbot? You need sub-second latency. Overnight batch analysis? Throughput matters more.
🔒 Security
Processing medical records? Run models on-prem. Public product reviews? Cloud APIs are fine.
🛠️ Capability
Code generation? Qwen-Coder is specialized. Image analysis? GPT-4V or Claude with vision.
💰 Cost
Processing 10M support tickets? Gemini Flash at $0.10/1M tokens. Strategic consulting? Spend on Claude Opus.
Here’s a real example from AWS: they built an educational tutor that routes history questions to Claude 3 Haiku (cheaper, faster) and math questions to Claude 3.5 Sonnet (better at complex problem-solving). Different subjects, different models.
And RouteLLM, an open-source routing framework, showed they could reduce costs by 85% on benchmarks while maintaining 95% of GPT-4’s quality—just by routing simple queries to cheaper models.
So how do you decide which request goes to which model?
Two Approaches: Rules vs Intent
Approach 1: Rule-Based Routing (The Old Way)
Most teams start with hard-coded rules:
if request.type == "code_generation":
route_to("qwen2.5-coder")
elif "security" in request.text or "vulnerability" in request.text:
route_to("claude-opus")
elif len(request.text) > 10000:
route_to("gpt-4-turbo")
else:
route_to("gemini-flash") # cheap defaultThis works for a week. Then it breaks:
- Someone asks “review this auth code for issues” (is that security? code generation? both?)
- Rules pile up: 50 if-statements checking keywords
- Rules conflict: security rules override code rules, but the request needs both
- Maintenance nightmare: every new use case = new rules
Approach 2: Intent-Aware Routing (The Smart Way)
What if instead of matching keywords, you use a model to understand what the user really wants?
That’s what NVIDIA’s Orchestrator-8B does. According to NVIDIA’s documentation, it uses flexible routing strategies—from task-based classification to user-intent analysis—analyzing each prompt for complexity, domain knowledge, and reasoning needs.
The breakthrough: It can identify multiple intents in a single request.
“Make this production-ready” doesn’t mean one thing. It means:
- Security scan (use fast pattern-matching model)
- Performance optimization (use specialized code model)
- Error handling (use reasoning model)
- Documentation (use writing model)
- Tests (use code generation model)
Five intents. Five different model choices. Your execution layer handles each one appropriately.
Important: This Is Just the Routing Layer
This experiment is not about building an agent execution engine. That’s what frameworks like LangGraph, AutoGen, and CrewAI are for. This is about the routing layer—understanding intent and recommending which model to use. Your execution framework handles the actual orchestration.
For more on governing agents in production, see my earlier work on agentic operating models and the broader agentic landscape.
Real Example: “Review This Auth Code”
Let me show you how this works. You’re launching a new feature and want your authentication code reviewed:
Your Request
“Review this authentication code for security vulnerabilities and generate fixes”
def login(username, password):
query = f"SELECT * FROM users WHERE username='{username}'"
result = db.execute(query)
if result and result[0]['password'] == password:
return create_session(result[0]['id'])
return NoneA rule-based system sees “security” and routes everything to Claude Opus at $15/1M tokens. Expensive.
An intent-aware system sees two distinct intents:
Intent 1: Security Analysis
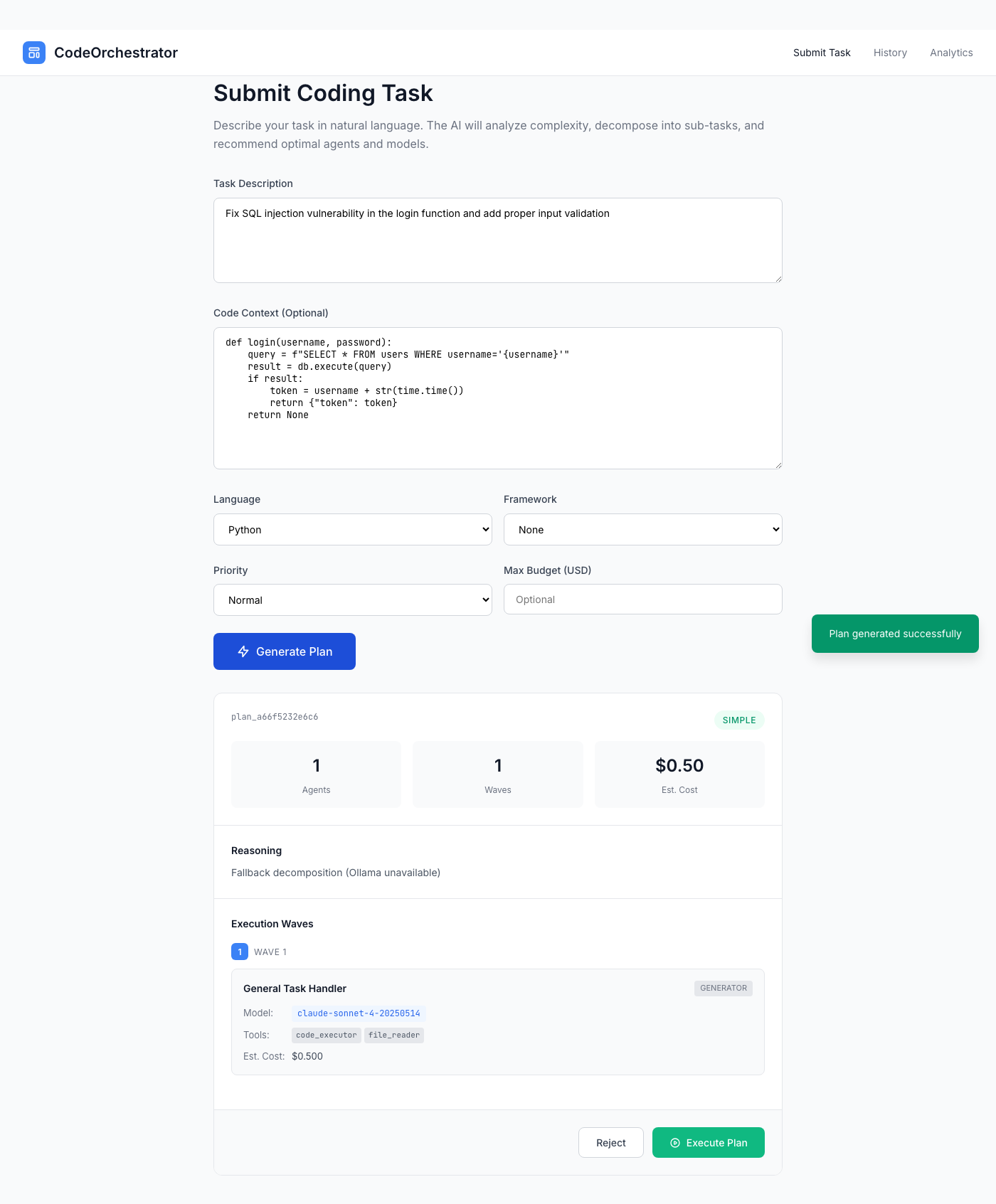
NVIDIA Orchestrator-8B breaking down the request into multiple intents with model recommendations
Recommended: Gemini 2.5 Flash
Why this model? Scanning for SQL injection and plaintext passwords is pattern matching—Gemini Flash excels at this
Cost: $0.10 per 1M tokens (150x cheaper than Claude Opus)
Speed: ~2 seconds for vulnerability scan
Intent 2: Code Generation
Recommended: Qwen2.5-Coder (Local)
Why this model? Specialized for code generation, runs locally (private + free)
Cost: $0 (local inference via Ollama)
Speed: ~5 seconds to generate parameterized query + bcrypt hashing
Dependency: Waits for security analysis to complete first
The Result

Execution showing model routing in action (your framework implements the actual orchestration)
Total Cost
$0.15
vs $3.50 using only Claude Opus
Time Saved
7s
Analysis + generation in parallel
95% cost reduction. Same quality. Faster execution.
Other Compound AI Systems
Intent-aware routing works across any compound AI system:
Customer Support (RAG System)
Request: “Customer reports login issues and wants refund for downtime”
Intents: Technical diagnosis + billing/refund + sentiment analysis
Components:
- Vector DB retrieval (find similar issues)
- Local model (privacy-first technical diagnosis)
- Cloud API (refund policy lookup)
- Sentiment analyzer (detect frustration level)
Routing: Parallel execution, privacy-aware model selection
Market Research (Multi-Step Chain)
Request: “Analyze competitor pricing strategies and recommend our positioning”
Intents: Data collection + quantitative analysis + strategic planning
Components:
- Web scraper (collect competitor data)
- Fast model (data normalization & stats)
- Mid-tier model (trend analysis)
- Premium model (strategic recommendations)
Routing: Sequential chain, cost optimization at each step
Content Production (AlphaCode-Style)
Request: “Create technical blog with SEO optimization and social adaptations”
Intents: Long-form writing + SEO + social media optimization
Components:
- Premium model (draft blog post)
- Fast model (generate 10 SEO variations)
- Specialized models (Twitter, LinkedIn, Instagram versions)
- Ranking model (select best SEO + social versions)
Routing: Mixed parallel/sequential, generate-and-filter pattern
Running NVIDIA Orchestrator-8B Locally
I’m running this on a Mac, which means I needed a quantized version to fit in memory and run fast enough for real-time routing.
Model Configuration
- Model: nvidia/orchestrator-8b
- Quantization: Q4_K_M (4-bit quantized)
- Platform: Ollama (local inference)
- Size: ~4.5GB (vs ~16GB full precision)
- Performance: ~2-3s per routing decision on M-series Mac
4-bit quantization reduces model size by 70% with minimal quality degradation. For routing decisions (which need understanding, not creativity), the quantized model performs identically to full precision.
What Worked
✅ Multi-Intent Detection Is Surprisingly Good
“Make this production-ready” correctly identifies 4-5 distinct intents (security, performance, testing, documentation, monitoring). This is critical—compound AI systems need to route each sub-task to the optimal model.
✅ Cost-Quality Trade-offs Are Smart
It understands when to spend: complex legal reasoning gets Claude Opus, simple classification gets Gemini Flash. When to use specialized models: code generation goes to Qwen-Coder. When to go local: sensitive data stays on-prem.
✅ Context Awareness Works
“Optimize this for performance” routes differently depending on context. Database query? Specialized SQL model. React component? Frontend performance model. Python API? Backend optimization model.
What Didn’t Work
❌ Vague Requests Produce Vague Routing
“Make this better” gives you generic intent detection with poor model recommendations. You need specificity: “Optimize database query performance,” “Add comprehensive error handling,” “Refactor for maintainability.”
❌ This Doesn’t Execute Anything
The orchestrator gives you a routing plan—which intents it found, which models to use, which tools you need. Your execution layer (LangGraph, AutoGen, CrewAI, custom framework) actually runs the workflow. This is just intelligent routing.
❌ Sometimes Over-Engineers Simple Tasks
“Fix typo in README” doesn’t need 4 intents (analysis, correction, review, documentation). Sometimes it’s just… a typo. The model occasionally over-decomposes trivial tasks.
Key Takeaways
- The future is compound AI systems: Berkeley researchers found that state-of-the-art results come from multiple interacting components, not monolithic models
- 60% of production LLM apps are compound systems: Using RAG, multi-step chains, and multi-model routing (Databricks research)
- Intent-aware routing beats rules: Understanding what users really want enables smarter model selection than keyword matching
- Multiple intents are common: Single requests often need 3-5 different capabilities, each optimally handled by different models
- Cost optimization happens automatically: RouteLLM showed 85% cost reduction while maintaining 95% quality—just by routing intelligently
- 8B models can route effectively: NVIDIA Orchestrator-8B (Q4_K_M quantized) runs locally and provides production-quality routing decisions
- This is just the routing layer: Use established frameworks (LangGraph, AutoGen, CrewAI) for the actual agent execution and orchestration
Sources & Further Reading
- The Shift from Models to Compound AI Systems – Berkeley AI Research (Feb 2024)
- What Are Compound AI Systems? – Databricks
- RouteLLM: Cost-Effective LLM Routing – LMSYS (85% cost reduction)
- Multi-LLM Routing Strategies – AWS (educational tutor example)
- LLM Router Blueprint – NVIDIA NIM
- Agentic Operating Model – How to govern agents in production
- Gemini Strategy – Agentic landscape perspective

Leave a comment